URL
URI
URI
URI,Uniform Recource Identifier,统一资源标识符,用一串字符明确标识一个特定的资源,URI 使用分层命名的方案来标识资源,这样的标识使得能够使用特定的协议通过网络与资源进行交互。URI 最常见的形式是 URL。
格式
URI 的表示形式是以协议名称作为开头,这样每种协议都能根据自己的规范内容来拓展 URI 的形式,URI 通用形式相当于这些协议规范的超集。
URI 通用的形式只包含主要的两部分:协议和路径
scheme://[authority]path[?query][#fragment]
权限信息部分authority由以下部分组成:
authority = [userinfo@]host[:port]

协议
协议名称由一系列字符组成,这些字符以字母开头,后跟字母,数字,加号(+),句点(。)或连字符(-)的任意组合。
| 方案 | 描述 |
|---|---|
data | Data URIs |
file | 指定主机上文件的名称 |
ftp | 文件传输协议 |
http/https | 超文本传输协议/安全的超文本传输协议 |
mailto | 电子邮件地址 |
ssh | 安全 shell |
tel | 电话 |
urn | 统一资源名称 |
view-source | 资源的源代码 |
ws/wss | (加密的) WebSocket 连接 |
权限
权限部分由双斜线引导//,权限部分是完全可选的。
userinfo:以用户名和密码组合的形式username:password,但是出于安全原因不建议任何时候在 URI 中包含密码host:主机部分可以用域名或者 IP 地址来表示,IPv4 必须用点分十进制格式,IPv6 必须放在方括号里面[]post:端口
路径
路径部分以斜线/进行分隔,如果 URI 包含userinfo部分,则路径必须为空或者以斜线开头/;如果没有userinfo,则路径不能为空,并且不能以斜线开头
查询
查询部分由?分隔,其形式一般是由分隔符进行分隔的键值对组成
| 查询定界符 | 例 |
|---|---|
&符(&) | key1=value1&key2=value2 |
分号(;) | key1=value1;key2=value2 |
片段
片段是一个 hash 值,使用#分隔,指向辅助资源的位置。如果资源是 HTML 文档,片段值通常是特定元素的id属性值,表示页面锚点位置。
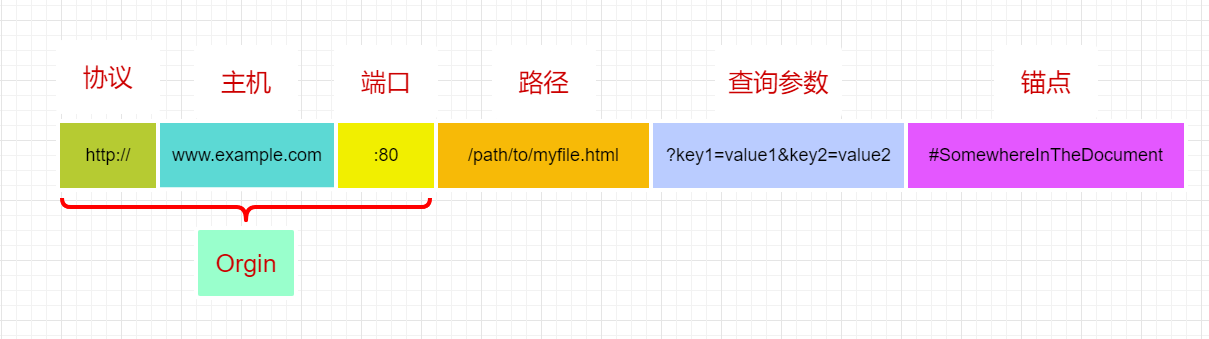
URL-HTTP
URL,Uniform Resource Locator,统一资源定位符,是表示 URI 的一种方式。URL 有多种协议,这种只讨论 HTTP 协议相关的。
-
主机:主机可以域名,也可以是 IP 地址。其中域名又分为顶级域名,二级域名和三级域名等等。
- 顶级域名:.com,.cn 这些
- 二级域名:google.com,google 属于二级域名
- 三级域名:google.com.hk,google 属于三级域名
-
端口:如果访问的该 Web 服务器使用 HTTP 协议的标准端口(HTTP 为
80,HTTPS 为443)授予对其资源的访问权限,则通常省略此部分。否则端口就是 URI 必须的部分。 -
路径:一般是 Wbe 服务器上文件路径的一部分,但是在
WebAPI中这个地址可以随意定义,遵循 RESTful 设计风格的 API 一般会使用名词表示路径。 -
查询参数查询参数是
?后面接的字符串部分,每部分参数使用&作为分隔符。 -
锚点:锚点一般是网页中的标题链接,使用
#后面接某个 HTML 标签内的文本内容,对于给定锚点链接的网页,在点击锚点地址后,浏览器会直接无刷新滚动到锚点所在位置。HTML5 启用了name属性,所以现在创建锚点的方式就是<a>标签的href设置为#id的形式,id就是要跳转的目标元素的 id 值。锚点的内容在请求的时候不会发送到服务器。
<h3 id="简单请求">简单请求</h3>
<a href="#简单请求">测试</a>
URL 编码 / 百分号编码
百分号编码(Percent-encoding)又称 URL 编码,形式就是百分号
%后跟十六进制数字[0,F]组成。
在 URL-http 中允许的字符必须是 ASCII 字符集中的字符,英文字母不区分大小写,但是英文字母建议用小写。而 ASCII 字符集又分为保留字符和非保留字符:
- 保留字符:在 URI 中具有特殊用法的字符,例如斜线字符
/用于分隔 URI 的不同部分,?用于串接参数,URI 中的保留字符有以下这些:/?#[]@:这几个字符永远定界符,即分隔 URI 不同部分;!$&'()*+,;=:这几个字符允许在host,path中作为分隔符
! * '' () ; : @ & = + $ , / ? # [ ]
- 非保留字符:也就是除了保留字符以外的其他 ASCII 字符,也就是大小写字母,数字等
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
a b c d e f g h i j k l m n o p q r s t u v w x y z
0 1 2 3 4 5 6 7 8 9
- _ . ~
如果在 URL 中将保留字符用于其他目的(例如斜线/不用做定界符),或者在 URL 中包含非 ASCII 字符,都需要进行编码处理,这里使用的是百分号编码。
保留字符的编码
如果是在 URL 中将 ASCII 保留字符用于其他目的(例如斜线/不用做定界符),那么就是对 ASCII 字符进行百分号编码;ASCII 字符本身只有单字节 8 位二进制,也就是能转成两个 16 进制数字,然后再前面加上百分号%即可表示百分比编码形式。
例如斜线/的 ASCII 值是 47,转二进制再每四位合并得到十六进制 2F,则斜线/的百分比编码就是%2F。
47 => 101111 => 101111 => 2F
所有保留字符的百分比编码如下:
':' | '/' | '?' | '#' | '[' | ']' | '@' | '!' | '$' | '&' | "'" | '(' | ')' | '*' | '+' | ',' | ';' | '=' | '%' | ' ' |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
%3A | %2F | %3F | %23 | %5B | %5D | %40 | %21 | %24 | %26 | %27 | %28 | %29 | %2A | %2B | %2C | %3B | %3D | %25 | %20 或 + |
空白字符的编码取决于不同情况:
-
在标准的 URI 形式中,空白字符会被编码成
%20。 -
在
enctype = application/x-www-form-urlencoded并且method = post提交的表单数据中,空格会使用+来替换; -
在表单使用默认的
method = get方式提交数据时,数据会串接在 URL 的查询字符串部分,此时空格也会使用+来替换
https://interactive-examples.mdn.mozilla.net/pages/tabbed/form.html?name=test+test&email=test%40gmail.com
非 ASCII 字符的编码
对于非 ASCII 字符在 URL 的编码如下:
- 首先得到其 UTF-8 编码值,
- 然后每个字节也就是每两个十六进制数前面加上百分号得到
%xx的形式 - 最后再合并
例如汉字我,Unicode 字符为U+6211,转 UTF-8 编码,再转百分比编码。
`U+6211` => 110 0010 0001 0001
//依次填入
1110xxxx 10xxxxxx 10xxxxxx
110 001000 010001
//得到
11100110 10001000 10010001
//转16进制
1110 0110 1000 1000 1001 0001
E 6 8 8 9 1
//UTF-8
E68891
//百分比编码
%e6%88%91
application/x-www-form-urlencoded
HTML 的<form>表单元素具有enctype属性,enctype 就是将表单的内容提交给服务器的 MIME 类型 ,这个属性的默认值是application/x-www-form-urlencoded。
当指定表单提交的方式method为post时,如果enctype 等于application/x-www-form-urlencoded,那么执行以下动作:
- 请求头的
Content-Type指定为application/x-www-form-urlencoded; - 表单的数据使用
&分隔的键值对形式key1=val1&key2=val2提交到服务器,键和属性值都会进行百分比编码,这也是这种形式不支持文件上传的原因,文件一般都是以二进制数据流上传,不能编码。
HTTP 请求体
POST http://www.example.com HTTP/1.1 Content-Type:
application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
JS 里的 URL 接口
Location 接口
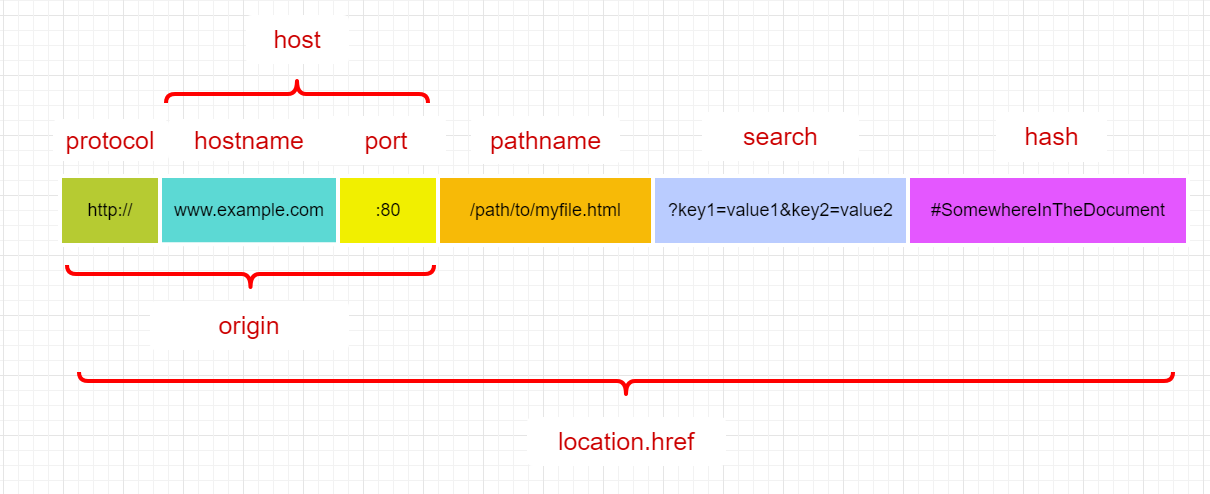
Location接口是 HTML5 规范定义的表示当前网页 URL 的接口,在 JS 中一般使用Document和Window接口的对象属性document.location和window.location来表示当前页面的Location对象,Location没有构造函数,拿来即用。
属性
Location根据 URL 的组成部分,划分了诸多属性:
Location.protocolLocation.hostnameLocation.portLocation.hostLocation.pathnameLocation.searchLocation.hashLocation.originRead onlyLocation.href
方法
Location下还提供了一些操作 URL 的方法:
location.assign(url):跳转到指定的url,history.push是无感的,但是location.assign会有跳转加载动画location.reload(forcedReload):重新加载当前页面,其接受一个boolean类型的参数,为true的时候就强制浏览器从服务器加载页面资源;否则浏览器可能从缓存中读取页面location.replace(url):跳转到指定url,会有跳转动画location.toString():该方法返回一个经过百分比编码的url
History
history和location的主要区别就是location会附带浏览器的页面跳转和加载动画效果,但是history是无刷新的。
属性
history.length:会话历史页面数目,包括当前页面;例如新开的标签页面,这个数目就是1history.state:历史会话状态数据history.scrollRestoration:储存回复页面滚动历史,如果这个值是auto则表示用户滚动到的页面位置将被恢复;如果这个值是manual则表示历史页面的滚动位置需要用户手动恢复
方法
history.back():回退上个历史页面,如果没有历史记录则不会发生任何改变history.go([delta]):接收一个整数作为参数,表示相对于当前页面的历史堆栈偏移量,从而跳转到那个页面;如果不传这相当于location.reload()history.forward():在会话历史记录中前进一页history.pushState(state, title [, url]):跳转到指定url,并携带会话状态参数state和指定的document.title。很多现代浏览器都直接忽略了title这个参数,例如chrome,firefox等history.replaceState(stateObj, title, [url]):以指定url和state替换当前页面
URL
构造函数
new URL(url [, base]):根据指定url字符串创建URL接口的对象,可选参数base表示相对的url
let m = 'https://developer.mozilla.org';
let a = new URL('/', m); // => 'https://developer.mozilla.org/'
属性
URL接口里的属性和Location差不多,不同点为:
-
URL接口不能直接使用,需要通过构造函数初始化创建URL对象才可以,从这点来说,location拿过来就能用更方便 -
Location没有这个searchParams这个属性
以下是URL接口包含的常用属性
protocal:协议host:域名hostname:域名 + 端口port:端口origin:协议,域名,端口pathname:/开头的路径search:?开头的查询字符串searchParams:URLSearchParams格式的查询对象,Location没有这个属性hash:#开头的锚点href:整个url,经过百分比编码的
方法
-
URL.createObjectURL(object):静态方法,根据指定的File,Blob,或者MediaSource创建URL对象并返回,可以用在img的src等属性中 -
URL.revokeObjectURL(objectURL):静态方法,将URL.createObjectURL创建的URL再转换成原始对象,通常和URL.createObjectURL一起使用 -
url.toString():返回经过百分比编码的url -
url.toJSON():返回经过百分比编码的url
URLSearchParams
URLSearchParams专门用来操作url.search部分的字符串
构造函数
new URLSearchParams(searchParams):创建一个URLSearchParams对象,可接受以下类型的参数:
// 普通字符串
var params2 = new URLSearchParams('foo=1&bar=2');
// location.search或者url.search
var params2a = new URLSearchParams('?foo=1&bar=2');
// 键值对形式的数组
var params3 = new URLSearchParams([
['foo', '1'],
['bar', '2'],
]);
// 对象
var params4 = new URLSearchParams({ foo: '1', bar: '2' });
方法
urlSearchParams.has(name):是否找得到指定属性urlSearchParams.get(name):返回指定的属性值,没找到就返回nullurlSearchParams.getAll(name):返回所有属性的值组成的数组urlSearchParams.set(name, value):设置某个属性的值urlSearchParams.append(name, value):向URLSearchParams对象添加键值对urlSearchParams.delete(name):删除URLSear chParams对象中指定属性urlSearchParams.forEach(fn):接受一个函数,函数的的参数是value和keyurlSearchParams.keys():返回一个可被for...of迭代的迭代器,每次遍历返回属性名称urlSearchParams.values():返回一个可被for...of迭代的迭代器,每次遍历返回属性的值urlSearchParams.entries():返回一个可被for...of迭代的迭代器,每次遍历返回当前键值对形式的数组urlSearchParams.sort():根据属性名称所在的 Unicode 码点值进行排序,这种排序算法是稳定的,即具有相同键的键/值对之间的相对顺序每次排序都是相同的
var paramsString = 'q=URLUtils.searchParams&topic=api';
var searchParams = new URLSearchParams(paramsString);
for (let p of searchParams) {
console.log(p);
}
searchParams.has('topic') === true; // true
searchParams.get('topic') === 'api'; // true
searchParams.getAll('topic'); // ["api"]
searchParams.get('foo') === null; // true
searchParams.append('topic', 'webdev');
searchParams.toString(); // "q=URLUtils.searchParams&topic=api&topic=webdev"
searchParams.set('topic', 'More webdev');
searchParams.toString(); // "q=URLUtils.searchParams&topic=More+webdev"
searchParams.delete('topic');
searchParams.toString(); // "q=URLUtils.searchParams"
JS 中的 URL 编码方法
在 ES 规范文档中提供两个标准的全局函数用于处理 URL 编码,encodeURI和encodeURIComponent,与他们分别对应的还有两个解码方法decodeURI和decodeURIComponent
encodeURI
encodeURI(str) ->
decodeURI
encodeURI不会对 ASCII 字符集中的以下字符进行编码,包括大小写英文字母,数字,URI 保留字符:
A-Z
a-z
0-9
- _ . ! ~ * ' ( ) ; , / ? : @ & = + $ #
encodeURIComponent
encodeURIComponent(str) ->
decodeURIComponent
encodeURIComponent不会对以下 71 个字符进行编码
A-Z
a-z
0-9
- _ . ! ~ * ' ( )
使用场景
encodeURI不会对 URL 中用于分隔的字符进行编码,而encodeURIComponent不编码的字符只有 71 个,其中用于分隔 URI 各部分的字符/,?,=,&,#等都会进行编码,所以
encodeURIComponent适合编码 URI 中的一部分内容,例如queryString部分,编码完了再和 URL 串接起来发送到后端去处理,encodeURIComponent使用的更多;- 如果你希望将整个 URL 放进另一个 URL 中去处理请求,这样就应该使用
encodeURIComponent了
console.log(
encodeURIComponent(
'http://www.example.com:8080/path1/path2?name=test&value=1#anchor',
),
);
// http%3A%2F%2Fwww.example.com%3A8080%2Fpath1%2Fpath2%3Fname%3Dtest%26value%3D1%23anchor
console.log(
encodeURI('http://www.example.com:8080/path1/path2?name=test&value=1#anchor'),
);
// http://www.example.com:8080/path1/path2?name=test&value=1#anchor
URL 的最大长度
URL 的长度问题其实不是太常涉及到,一般来说不太了解 HTTP GET请求方法的人喜欢将URL长度限制这种结论归结到GET请求的不足中去。
根据 stackoverflow 提问 —— What is the maximum length of a URL in different browsers,该问题的第一个回答大致可以看出 HTTP 方面并没有限制 URI 长度的规定,但是不同浏览器对 URL 的限制长度不同,并且服务器方面也会有限制,当服务器无法处理超长 URL 时,应该返回414状态码表示请求的 URL 过长。同时答案也建议 URL 控制在2000个字符以内,这样基本能满足不同浏览器和服务器的限制。
| 浏览器 | 长度限制 |
|---|---|
| Chrome | 2M,超出后不会尝试打开页面 |
| FireFox | 1M,超出后报异常也不会打开页面 |
| Safari | 无限制 |
| IE | IE11 之前是 2083 个字符,IE11 以后是 2048 个字符 |
| 服务器 | 限制 |
|---|---|
| nginx - large_client_header_buffers | 默认是 8kB,可以手动配置修改 |
| apache | 默认是 8190,8 KB |
| Tomcat - maxHttpHeaderSize | 默认是 8192 ,8 KB |